
安装
yum安装
#创建目录
[root@andrew ~]cd /etc/yum.repos.d/
#下载安装包
[root@andrew yum.repos.d]curl -OL https://download.arangodb.com/arangodb312/RPM/arangodb.repo
#解压安装包
[root@andrew yum.repos.d]yum -y install arangodb3-3.12.4-1.3
#启动
[root@andrew yum.repos.d]systemctl start arangodb3
#查看状态
[root@andrew yum.repos.d]systemctl status arangodb3但是这时候访问不了web页面!!!
① 编辑配置文件
vi /etc/arangodb3/arangod.conf找到并确认这部分配置(可能在 [server] 段):
endpoint = tcp://0.0.0.0:8529✅ 确保是 0.0.0.0,不是 127.0.0.1 ✅ 确保这行没有被注释(前面没有 #)
② 保存后重启服务
systemctl restart arangodb3然后执行:
ss -tulnp | grep 8529表示已经监听所有 IP 地址,远程访问就正常了!
用docker安装(推荐)
不过要先安装docker
docker run -e ARANGO_ROOT_PASSWORD=test123 -p 8529:8529 -d arangodb
#记得打开安全组
#账号:root
#密码:test123访问web界面
浏览器访问 http://服务器公网ip:8529/即可
基础操作
Structure
database:数据库
collections:集合(相当于sql里的表)
document:文件(相当于sql里的一行)
一个数据库可以包含多个collections,一个collection可以包含多个document
字段类型
nullboolean (
true,false)number (integer and floating point values)
string
array
object
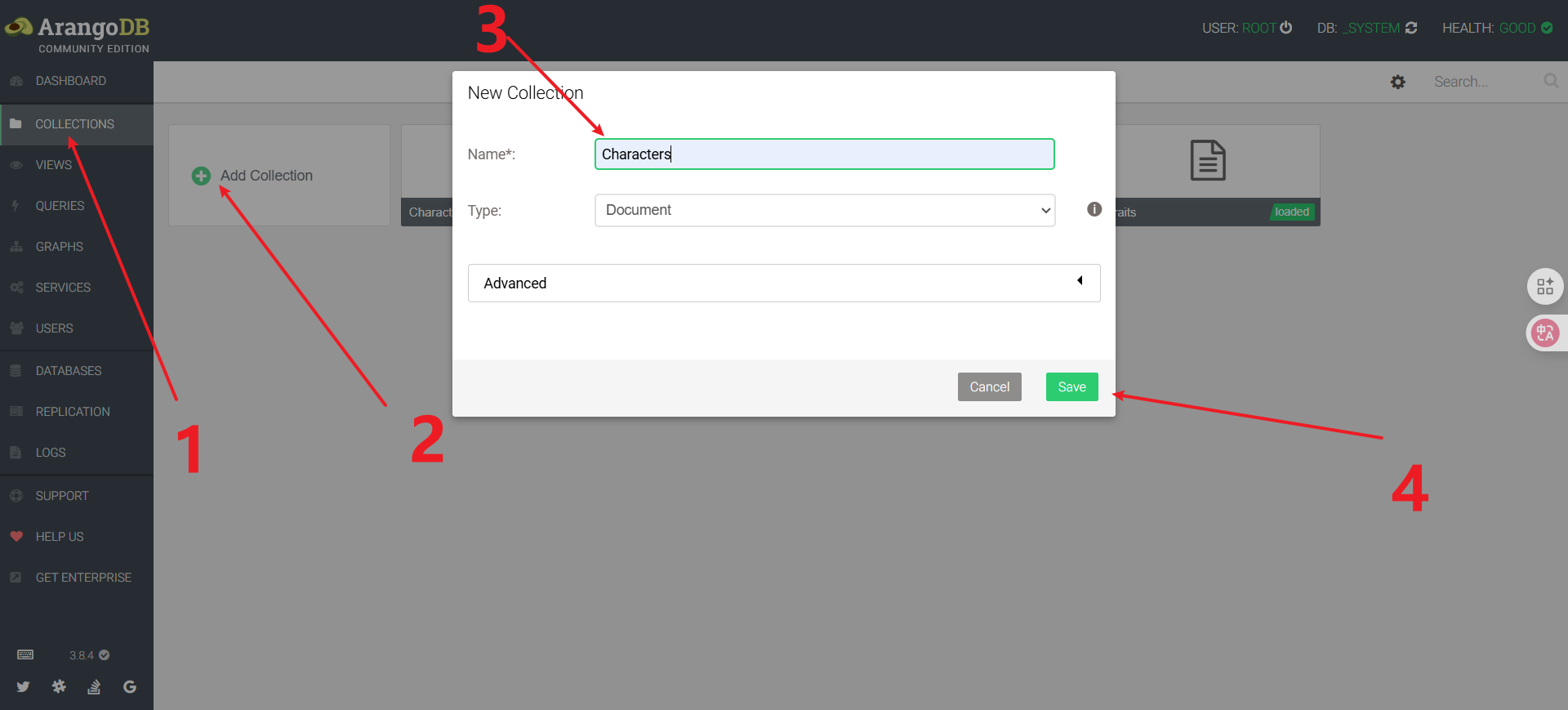
创建Collection
创建一个collection叫Characters
特殊字段
_id:全局id,(表名/主键)
_key:主键
_rev:版本号,系统自动生成

AQL基础语法
AQL对关键字是不区分大小写的,但对变量名、集合名、字段名大小写敏感
Creat
点集合
INSERT {
_key: "test",
name: "First",
surname: "Test",
alive: false,
age: 123,
traits: [ "X", "Y" ]
} INTO Characters RETURN NEW
#RETURN NEW 是返回看看怎么样有返回
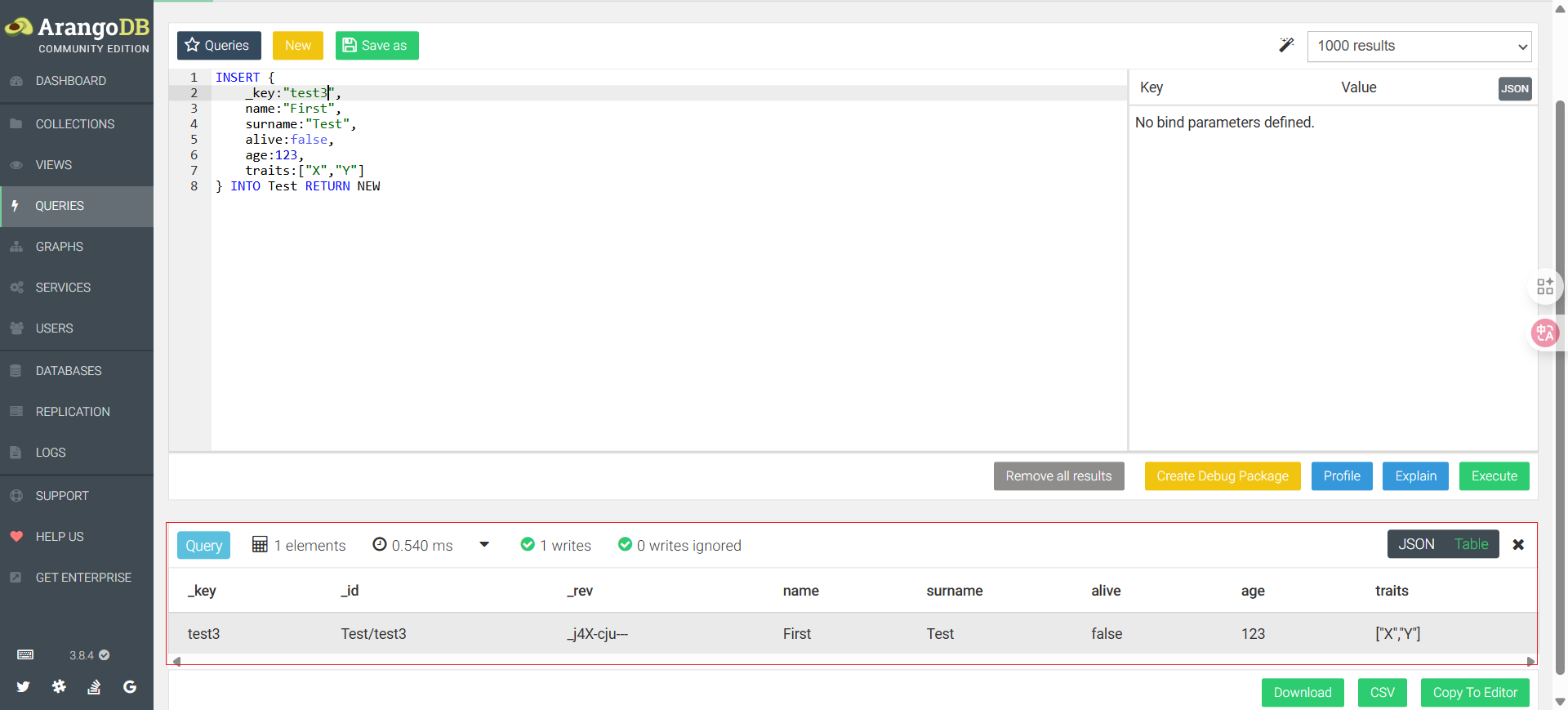
无返回
与sql不同:
同一个Collection中可以出现不同类型的documet(行)
但是mysql的话每一行的属性都是相同的,没填充的就为null。
mysql就是一张表,Collection就像一个圆,每个document都是一个不同的圆
但是我们默认还是一个collection中还是放类型相同的document
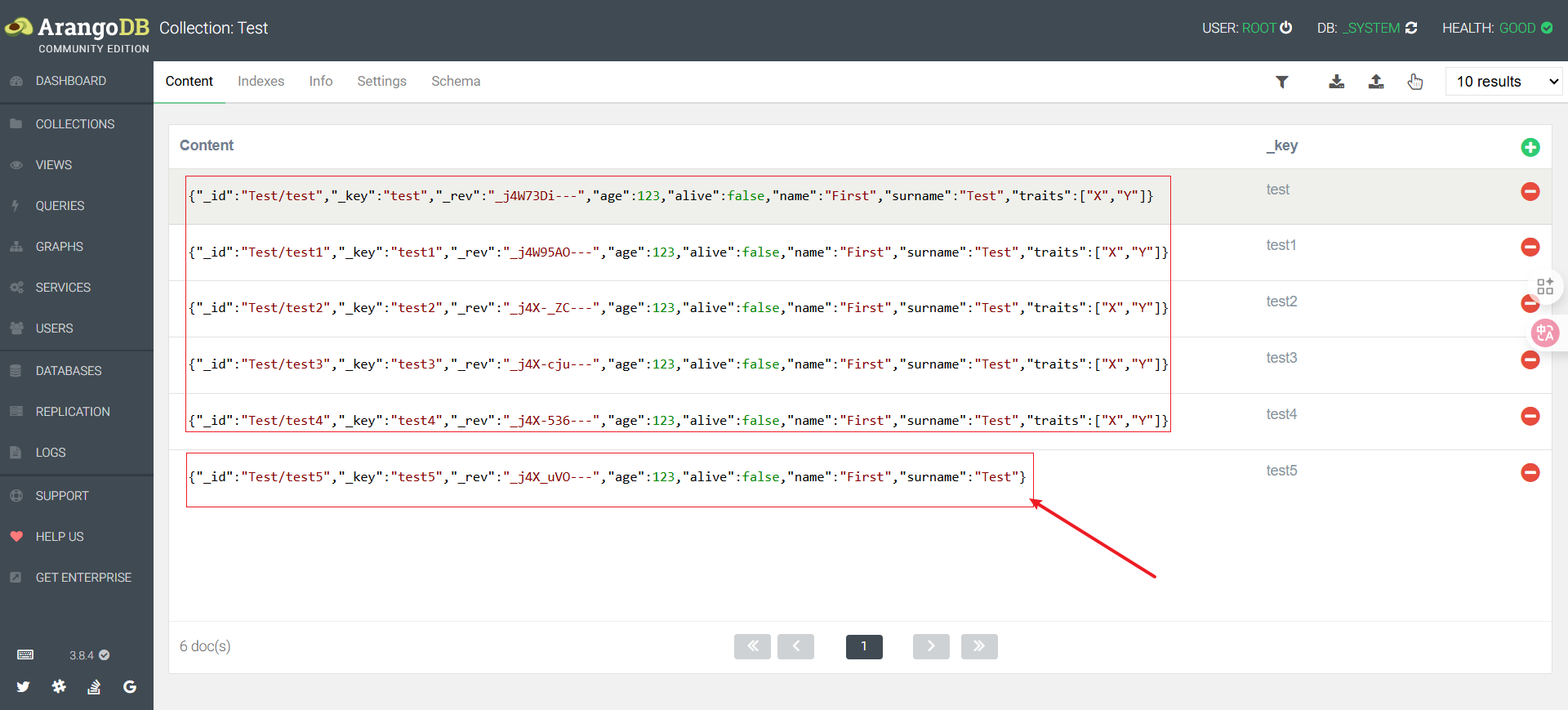
FOR d IN @data
INSERT d INTO Characters
#他会将data一个个插入到Characters中 [
{ "_key": "ned", "name": "Ned", "surname": "Stark", "alive": true, "age": 41, "traits": ["A","H","C","N","P"] },
{ "_key": "robert", "name": "Robert", "surname": "Baratheon", "alive": false, "traits": ["A","H","C"] },
{ "_key": "jaime", "name": "Jaime", "surname": "Lannister", "alive": true, "age": 36, "traits": ["A","F","B"] },
{ "_key": "catelyn", "name": "Catelyn", "surname": "Stark", "alive": false, "age": 40, "traits": ["D","H","C"] },
{ "_key": "cersei", "name": "Cersei", "surname": "Lannister", "alive": true, "age": 36, "traits": ["H","E","F"] },
{ "_key": "daenerys", "name": "Daenerys", "surname": "Targaryen", "alive": true, "age": 16, "traits": ["D","H","C"] },
{ "_key": "jorah", "name": "Jorah", "surname": "Mormont", "alive": false, "traits": ["A","B","C","F"] },
{ "_key": "petyr", "name": "Petyr", "surname": "Baelish", "alive": false, "traits": ["E","G","F"] },
{ "_key": "viserys", "name": "Viserys", "surname": "Targaryen", "alive": false, "traits": ["O","L","N"] },
{ "_key": "jon", "name": "Jon", "surname": "Snow", "alive": true, "age": 16, "traits": ["A","B","C","F"] },
{ "_key": "sansa", "name": "Sansa", "surname": "Stark", "alive": true, "age": 13, "traits": ["D","I","J"] },
{ "_key": "arya", "name": "Arya", "surname": "Stark", "alive": true, "age": 11, "traits": ["C","K","L"] },
{ "_key": "robb", "name": "Robb", "surname": "Stark", "alive": false, "traits": ["A","B","C","K"] },
{ "_key": "theon", "name": "Theon", "surname": "Greyjoy", "alive": true, "age": 16, "traits": ["E","R","K"] },
{ "_key": "bran", "name": "Bran", "surname": "Stark", "alive": true, "age": 10, "traits": ["L","J"] },
{ "_key": "joffrey", "name": "Joffrey", "surname": "Baratheon", "alive": false, "age": 19, "traits": ["I","L","O"] },
{ "_key": "sandor", "name": "Sandor", "surname": "Clegane", "alive": true, "traits": ["A","P","K","F"] },
{ "_key": "tyrion", "name": "Tyrion", "surname": "Lannister", "alive": true, "age": 32, "traits": ["F","K","M","N"] },
{ "_key": "khal", "name": "Khal", "surname": "Drogo", "alive": false, "traits": ["A","C","O","P"] },
{ "_key": "tywin", "name": "Tywin", "surname": "Lannister", "alive": false, "traits": ["O","M","H","F"] },
{ "_key": "davos", "name": "Davos", "surname": "Seaworth", "alive": true, "age": 49, "traits": ["C","K","P","F"] },
{ "_key": "samwell", "name": "Samwell", "surname": "Tarly", "alive": true, "age": 17, "traits": ["C","L","I"] },
{ "_key": "stannis", "name": "Stannis", "surname": "Baratheon", "alive": false, "traits": ["H","O","P","M"] },
{ "_key": "melisandre", "name": "Melisandre", "alive": true, "traits": ["G","E","H"] },
{ "_key": "margaery", "name": "Margaery", "surname": "Tyrell", "alive": false, "traits": ["M","D","B"] },
{ "_key": "jeor", "name": "Jeor", "surname": "Mormont", "alive": false, "traits": ["C","H","M","P"] },
{ "_key": "bronn", "name": "Bronn", "alive": true, "traits": ["K","E","C"] },
{ "_key": "varys", "name": "Varys", "alive": true, "traits": ["M","F","N","E"] },
{ "_key": "shae", "name": "Shae", "alive": false, "traits": ["M","D","G"] },
{ "_key": "talisa", "name": "Talisa", "surname": "Maegyr", "alive": false, "traits": ["D","C","B"] },
{ "_key": "gendry", "name": "Gendry", "alive": false, "traits": ["K","C","A"] },
{ "_key": "ygritte", "name": "Ygritte", "alive": false, "traits": ["A","P","K"] },
{ "_key": "tormund", "name": "Tormund", "surname": "Giantsbane", "alive": true, "traits": ["C","P","A","I"] },
{ "_key": "gilly", "name": "Gilly", "alive": true, "traits": ["L","J"] },
{ "_key": "brienne", "name": "Brienne", "surname": "Tarth", "alive": true, "age": 32, "traits": ["P","C","A","K"] },
{ "_key": "ramsay", "name": "Ramsay", "surname": "Bolton", "alive": true, "traits": ["E","O","G","A"] },
{ "_key": "ellaria", "name": "Ellaria", "surname": "Sand", "alive": true, "traits": ["P","O","A","E"] },
{ "_key": "daario", "name": "Daario", "surname": "Naharis", "alive": true, "traits": ["K","P","A"] },
{ "_key": "missandei", "name": "Missandei", "alive": true, "traits": ["D","L","C","M"] },
{ "_key": "tommen", "name": "Tommen", "surname": "Baratheon", "alive": true, "traits": ["I","L","B"] },
{ "_key": "jaqen", "name": "Jaqen", "surname": "H'ghar", "alive": true, "traits": ["H","F","K"] },
{ "_key": "roose", "name": "Roose", "surname": "Bolton", "alive": true, "traits": ["H","E","F","A"] },
{ "_key": "high-sparrow", "name": "The High Sparrow", "alive": true, "traits": ["H","M","F","O"] }
]
边集合
LET relations = [
{ "parent": "ned", "child": "robb" },
{ "parent": "ned", "child": "sansa" },
{ "parent": "ned", "child": "arya" },
{ "parent": "ned", "child": "bran" },
{ "parent": "catelyn", "child": "robb" },
{ "parent": "catelyn", "child": "sansa" },
{ "parent": "catelyn", "child": "arya" },
{ "parent": "catelyn", "child": "bran" },
{ "parent": "ned", "child": "jon" },
{ "parent": "tywin", "child": "jaime" },
{ "parent": "tywin", "child": "cersei" },
{ "parent": "tywin", "child": "tyrion" },
{ "parent": "cersei", "child": "joffrey" },
{ "parent": "jaime", "child": "joffrey" }
]
FOR rel in relations
INSERT {
_from: CONCAT("Characters/", rel.child),
_to: CONCAT("Characters/", rel.parent)
} INTO ChildOf
RETURN NEWconcat是连接函数,
Read
全表查询
FOR c IN Characters
RETURN c条件查询
利用函数document
RETURN DOCUMENT("Characters/arya")一次获取多个文档
RETURN DOCUMENT("Characters",["arya","bran"])
RETURN DOCUMENT(["A/2861650", "B/2861653"])#这会返回空,不支持两个不同表
RETURN DOCUMENT(["A/2861650", "A/2861653"])#这个是可以的Update
单个字段更新
UPDATE "ned" WITH { alive: false } IN Characters
#这应该很简单吧 update多个字段更新
UPDATE "arya" WITH {
age:12,
alive:false
} IN Characters全部更新用replace
REPLACE "ned" WITH {
name: "Ned",
surname: "Stark",
alive: false,
age: 41,
traits: ["A","H","C","N","P"]
} IN Characters还可以用for对characters中所有documents进行更新
FOR c IN Characters
UPDATE c WITH { season: 1 } IN CharactersDelete
REMOVE "test" IN Characters删除all document
FOR c IN Characters
REMOVE c IN Characters查询
filter
相当于sql里的where
FOR c IN Characters
FILTER c.name == "Ned"
RETURN c多条件:
FILTER后面不用加
,因为本质上是一行独立的语句是==而不是=
return{}可以选字段名(相当于select)
{里面必须是JSON格式},但是单个就不用(没必要)
FOR c IN Characters
FILTER c.age > 10
FILTER c.alive == true
return {name:c.name,age:c.age}sort和limit
FOR c in Characters
limit 5
return c
#返回前5个 FOR c in CHaracters
limit 2.5
return c
#从第二个起,返回5个 FOR c in Characters
limit 2,5
sort c.age DESC
return c
#为什么条件里都要指明c.age而不是age
#AQL更像是JavaScript,需要通过对象来引用。c为对象,age为字段document
return document("集合名",键或者键数组) for c in Characters
return document("Characters","arya")从Characters中取出key为arya的文档
FOR c IN Characters
RETURN DOCUMENT("Traits", c.traits)c.traits是一个数组
这里是对应Characters中的all document,返回c.traits在Traits中对应的值
数组
FOR c IN Characters
RETURN DOCUMENT("Traits", c.traits)[*].enDOCUMENT("Traits", c.traits) 返回的是一个数组,[*].en 之挑出数组里的en
merge
FOR c IN Characters
RETURN MERGE(c, { traits: DOCUMENT("Traits", c.traits)[*].en } )merge会将两个对象合并,并且第二个对象中的参数会覆盖前一个对象的同名字段
{ traits: DOCUMENT("Traits", c.traits)[*].en } 这相当于一个对象了
LET
LET variableName = expression
expression可以是值,也可以是表达式
数组
p.vertices[*]:对路径中的所有顶点(vertices)进行迭代
LET arr = p.vertices[]
PRUNE
一句话理解 PRUNE
PRUNE是 剪枝条件,如果条件为true,则 这条路径不再往下遍历(提前停止),不会再继续找它的下一跳。
与之相对的是 FILTER:
函数
IS_SAME_COLLECTION
一般和FILTER连用
LET customerNodes = p.vertices[* FILTER IS_SAME_COLLECTION('cust_info_document', CURRENT)]
p.vertices[*]指路径的顶点
* FILTER IS_SAME_COLLECTION('cust_info_document', CURRENT) 筛选出在该集合的点
APPEND
当然!我来详细解释下 ArangoDB AQL 中的 APPEND 函数:
什么是 APPEND
APPEND是 AQL 里的一个数组函数。作用是把两个数组合并成一个新的数组。
它返回一个包含第一个数组所有元素,后面跟着第二个数组所有元素的新数组。
语法
APPEND(array1, array2, [overwrite])array1:第一个数组array2:第二个数组[overwrite](可选,布尔值):当两个数组中有同名属性(针对数组元素是对象时)是否覆盖,默认是false。 — 只针对合并对象数组有意义,普通合并数组不用管。
示例
LET a = [1, 2, 3]
LET b = [4, 5]
RETURN APPEND(a, b) // 结果:[1, 2, 3, 4, 5]你的用法示例说明
你写:
LET allowedRelationTypes = APPEND(
APPEND(
1 IN [1, 2, 3] ? ['亲属关系'] : [],
2 IN [1, 2, 3] ? ['企业及经营关系'] : []
),
3 IN [1, 2, 3] ? ['担保关系'] : []
)先判断数字
1是否在数组[1,2,3]中,如果是,生成['亲属关系'],否则空数组[]同理判断
2,生成['企业及经营关系']或空数组使用第一个
APPEND把上面两数组合并再用第二个
APPEND把判断数字3对应的数组追加进来最终得到一个数组,包含所有满足条件的关系类型字符串
总结
APPEND用于数组合并,是“连接”两个数组的函数。它不会去重,如果你想去重要用
UNION函数。它在你的场景中很合适,用来根据条件逐步构造一个数组。
如果你想要我帮你写更多例子,或者讲解类似的数组函数,随时告诉我!
FLATTERN
FLATTEN([
1 IN [1, 2, 3] ? ['亲属关系'] : [],
2 IN [1, 2, 3] ? ['企业及经营关系'] : [],
3 IN [1, 2, 3] ? ['担保关系'] : []
])边的遍历
基础
FOR v, e, p IN 1..2 ANY "cust_info_document/ID002" subject_relations
OPTIONS { bfs: true, uniqueVertices: 'path' }
return vfor指遍历图
1..1指最少走一步,最多走2步
OUTBOUND|INBOUND|ANY:指明遍历的方向
"Characters/bran" : 指从这个点开始
ChildOf指从这个图来遍历
遍历顺序
默认是dfs
bfs: true :这样开启bfs
uniqueVertices
在 ArangoDB 的 AQL(ArangoDB Query Language)中,uniqueVertices 选项用于控制图遍历时顶点的唯一性。uniqueVertices 选项可以设置为 'path' 或 'global',它们的区别在于如何处理遍历过程中的顶点唯一性。
uniqueVertices: 'path'
含义:在单条路径上,每个顶点最多出现一次。
行为:在遍历过程中,如果一个顶点已经在当前路径中出现过,那么它不会再次被访问。这确保了每条路径中的顶点是唯一的,但不同的路径可以共享相同的顶点。
适用场景:当你希望避免在单条路径中重复访问同一个顶点时,但允许不同的路径可以访问同一个顶点。这在许多图遍历场景中非常有用,例如在社交网络中查找最短路径时。
uniqueVertices: 'global'
含义:在整个遍历过程中,每个顶点最多出现一次。
行为:在遍历过程中,如果一个顶点已经在任何路径中出现过,那么它不会再次被访问。这确保了在整个遍历过程中,每个顶点只被访问一次。
适用场景:当你希望在整个遍历过程中避免重复访问同一个顶点时,这在某些特定的图遍历场景中非常有用,例如在查找所有不重复顶点的路径时。
示例
假设有一个简单的图,包含以下顶点和边:
A --1--> B --2--> C
A --3--> C使用 uniqueVertices: 'path'
FOR v, e, p IN 1..2 ANY 'vertices/A' edges OPTIONS { uniqueVertices: 'path' }
RETURN { vertex: v, edge: e, path: p }结果:
路径1: A -> B -> C
路径2: A -> C
在这个例子中,顶点 C 在两条路径中都出现了,但每条路径中的顶点是唯一的。
使用 uniqueVertices: 'global'
FOR v, e, p IN 1..2 ANY 'vertices/A' edges OPTIONS { uniqueVertices: 'global' }
RETURN { vertex: v, edge: e, path: p }结果:
路径1: A -> B -> C
在这个例子中,顶点 C 只在一条路径中出现,因为一旦 C 被访问过,它就不会再被访问。
总结
uniqueVertices: 'path':确保每条路径中的顶点是唯一的,但不同的路径可以共享相同的顶点。uniqueVertices: 'global':确保在整个遍历过程中,每个顶点只被访问一次。
选择哪种选项取决于你的具体需求。如果你希望避免在单条路径中重复访问同一个顶点,但允许不同的路径可以访问同一个顶点,使用 uniqueVertices: 'path'。如果你希望在整个遍历过程中避免重复访问同一个顶点,使用 uniqueVertices: 'global'。
return
return v:指返回遍历的节点
return e:指返回遍历的边
return P:指返回遍历的路径
这个p和e主要在于返回的JSON不同
e的
[
{
"_key": "204467384",
"_id": "subject_relations/204467384",
"_from": "cust_info_document/ID002",
"_to": "project_info_document/projectA",
"_rev": "_jvruexm--A",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "担保关系",
"asso_type_sub": "反担保人",
"data_source": 1
},
{
"_key": "204467385",
"_id": "subject_relations/204467385",
"_from": "cust_info_document/ID002",
"_to": "project_info_document/projectB",
"_rev": "_jvruexm--C",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "担保关系",
"asso_type_sub": "借款人",
"data_source": 1
},
{
"_key": "205003683",
"_id": "subject_relations/205003683",
"_from": "cust_info_document/ID002",
"_to": "project_info_document/projectE",
"_rev": "_jvruexq--O",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "担保关系",
"asso_type_sub": "反担保人",
"data_source": 2
},
{
"_key": "204467395",
"_id": "subject_relations/204467395",
"_from": "cust_info_document/ID001",
"_to": "cust_info_document/ID002",
"_rev": "_jvruexq--K",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "亲属关系",
"asso_type_sub": "配偶",
"data_source": 2
}
]p的,边在前,两个点在后(既有边又有点)
[
{
"edges": [
{
"_key": "204467384",
"_id": "subject_relations/204467384",
"_from": "cust_info_document/ID002",
"_to": "project_info_document/projectA",
"_rev": "_jvruexm--A",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "担保关系",
"asso_type_sub": "反担保人",
"data_source": 1
}
],
"vertices": [
{
"_key": "ID002",
"_id": "cust_info_document/ID002",
"_rev": "_jvrNlp2--A",
"_class": "com.ludan.asso.api.dto.CustInfoDocument",
"create_time": "2025-05-29T09:19:05.289Z",
"cust_id_no": "ID002",
"cust_name": "客户2",
"cust_type": "个人",
"update_time": "2025-05-29T09:19:05.289Z"
},
{
"_key": "projectA",
"_id": "project_info_document/projectA",
"_rev": "_jvrk7FC---",
"_class": "com.ludan.asso.api.dto.ProjectInfoDocument",
"apply_no": "PA001",
"project_id": "projectA",
"source": "线上"
}
]
},
{
"edges": [
{
"_key": "204467385",
"_id": "subject_relations/204467385",
"_from": "cust_info_document/ID002",
"_to": "project_info_document/projectB",
"_rev": "_jvruexm--C",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "担保关系",
"asso_type_sub": "借款人",
"data_source": 1
}
],
"vertices": [
{
"_key": "ID002",
"_id": "cust_info_document/ID002",
"_rev": "_jvrNlp2--A",
"_class": "com.ludan.asso.api.dto.CustInfoDocument",
"create_time": "2025-05-29T09:19:05.289Z",
"cust_id_no": "ID002",
"cust_name": "客户2",
"cust_type": "个人",
"update_time": "2025-05-29T09:19:05.289Z"
},
{
"_key": "projectB",
"_id": "project_info_document/projectB",
"_rev": "_jvrk7FC--A",
"_class": "com.ludan.asso.api.dto.ProjectInfoDocument",
"apply_no": "PB001",
"project_id": "projectB",
"source": "线下"
}
]
},
{
"edges": [
{
"_key": "205003683",
"_id": "subject_relations/205003683",
"_from": "cust_info_document/ID002",
"_to": "project_info_document/projectE",
"_rev": "_jvruexq--O",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "担保关系",
"asso_type_sub": "反担保人",
"data_source": 2
}
],
"vertices": [
{
"_key": "ID002",
"_id": "cust_info_document/ID002",
"_rev": "_jvrNlp2--A",
"_class": "com.ludan.asso.api.dto.CustInfoDocument",
"create_time": "2025-05-29T09:19:05.289Z",
"cust_id_no": "ID002",
"cust_name": "客户2",
"cust_type": "个人",
"update_time": "2025-05-29T09:19:05.289Z"
},
{
"_key": "projectE",
"_id": "project_info_document/projectE",
"_rev": "_jvrk7FC--G",
"project_id": "projectE",
"apply_no": "PE001",
"source": "线上",
"_class": "com.ludan.asso.api.dto.ProjectInfoDocument"
}
]
},
{
"edges": [
{
"_key": "204467395",
"_id": "subject_relations/204467395",
"_from": "cust_info_document/ID001",
"_to": "cust_info_document/ID002",
"_rev": "_jvruexq--K",
"_class": "com.ludan.asso.api.dto.SubjectRelation",
"asso_type_main": "亲属关系",
"asso_type_sub": "配偶",
"data_source": 2
}
],
"vertices": [
{
"_key": "ID002",
"_id": "cust_info_document/ID002",
"_rev": "_jvrNlp2--A",
"_class": "com.ludan.asso.api.dto.CustInfoDocument",
"create_time": "2025-05-29T09:19:05.289Z",
"cust_id_no": "ID002",
"cust_name": "客户2",
"cust_type": "个人",
"update_time": "2025-05-29T09:19:05.289Z"
},
{
"_key": "ID001",
"_id": "cust_info_document/ID001",
"_rev": "_jvrNlp2---",
"_class": "com.ludan.asso.api.dto.CustInfoDocument",
"create_time": "2025-05-29T09:19:05.289Z",
"cust_id_no": "ID001",
"cust_name": "客户1",
"cust_type": "个人",
"update_time": "2025-05-29T09:19:05.289Z"
}
]
}
] FOR c IN Characters
FILTER c.surname == "Baratheon" AND c.age != null
FOR v IN 1..1 OUTBOUND c ChildOf
RETURN v.name找出Characters中surname为"Baratheon"且age不为null的document。再从这个document开始沿图遍历
区别
FOR c IN Characters
FILTER c.surname == "Lannister"
RETURN (FOR v IN 0..1 OUTBOUND c ChildOf
RETURN v.name)
FOR c IN Characters
FILTER c.surname == "Lannister"
FOR v IN 0..1 OUTBOUND c ChildOf
RETURN v.name
最好用第一个吧,把每个遍历的列表单独返回
反向遍历
FOR c IN Characters
FILTER c.name == "Ned"
FOR v IN 1..1 INBOUND c ChildOf
RETURN v.nameINBOUND:从to到from
但是他返回了两次
[
"Joffrey",
"Joffrey"
]这是因为有两条路径,一条是瑟曦,一条是詹姆
我们可以通过加个 DISTINCT 来解决
FOR c IN Characters
FILTER c.name == "Ned"
FOR v IN 1..1 INBOUND c ChildOf
RETURN DISTINCT v.nameSpringBoot的集成ArangoDB
依赖
<dependency>
<groupId>com.arangodb</groupId>
<artifactId>arangodb-spring-data</artifactId>
<version>3.8.0</version>
</dependency>
<dependency>
<groupId>com.arangodb</groupId>
<artifactId>arangodb-java-driver</artifactId>
<version>6.20.0</version> <!-- 必须与 arangodb-spring-data 3.8.0 兼容 -->
</dependency>
<dependency>
<groupId>com.arangodb</groupId>
<artifactId>arangodb-spring-boot-starter</artifactId>
<version>2.3.3.RELEASE</version>
<exclusions>
<exclusion>
<artifactId>arangodb-spring-data</artifactId>
<groupId>com.arangodb</groupId>
</exclusion>
</exclusions>
</dependency>arangodb-spring-boot-starter这个 Starter 包含了自动配置功能,可以自动加载和配置 ArangoDB 相关的属性。
它会自动创建
ArangoDB和ArangoTemplate的 Bean,简化了手动配置的步骤。
arangodb-spring-data这个依赖提供了 Spring Data 的集成,允许你使用 Spring Data 的方式操作 ArangoDB。(对象操作数据库,像JDBC一样)
arangodb-java-driver这是 ArangoDB 的 Java 驱动程序,提供了与 ArangoDB 数据库通信的功能。
配置
配置文件即application不可以报黄或报红,一点都不行,大部分报黄都是因为pom.xml里的依赖少了,导致springboot无法自动配置,启动肯定会报错
spring:
data:
arangodb:
hosts: 47.108.159.244:8529
user: root
password: "test123"
database: _system
实体类
@Data
@Document(collection = "Characters")
public class Characters {
@ArangoId
private String id;
@Field("name")
private String name;
@Field("surname")
private String surname;
@Field("alive")
private boolean alive;
@Field("age")
private int age;
@Field("traits")
private List<String> traits;
}Controller层
@RestController
public class CollectionsController {
@Autowired
private CharactersService charactersService;
@GetMapping("/Characters")
public List<Characters> getAllCharacters(){
return charactersService.getAllCharacters();
}
@GetMapping("/name")
public Characters getByName(@RequestParam String name){
return charactersService.getByName(name);
}
}Service层
public interface CharactersService {
List<Characters> getAllCharacters();
Characters getByName(String name);
} @Service
@Slf4j
@RequiredArgsConstructor
public class CharactersServiceImpl implements CharactersService {
private final CharactersRepository charactersRepository;
@Override
public List<Characters> getAllCharacters() {
return (List<Characters>) charactersRepository.findAll();
}
@Override
public Characters getByName(String name) {
return charactersRepository.geByName(name);
}
}Repository层
这里不用加@Mapper那样,因为继承的类以及springboot会帮我们加的
ArangoRepository<Characters, String> Characters这一般指我们要返回的Java实体类,这是调用系统自己的函数
但是加上@Query注解的话,还可以构建复制查询
public interface CharactersRepository extends ArangoRepository<Characters, String> {
@Query("for c in Characters " +
"FILTER c.name == @name " +
"return c")
Characters geByName(@Param("name") String name);
}

